java八大基础类型在JVM中是如何输入输入数据?jvm的存储区域是怎样划分的呢?jvm如何能快速找到你需要的对象,又是如何快速清除不需要的对象呢….
基本数据类型
-
1,基本数据类型
- java有八大基本数据类型 byte char/short int/long/boolean/float/double
- byte : 1字节
- short\char 2字节
- int :4字节
- long : 8字节
- float : 4字节
- double : 8字节
- boolean : 1字节
-
2,二进制运算预热
-
chapter1· 一些基础概念
-
机器数: 八位元组,用最高位表示符号位的二进制数,即为机器数. 0表示正数,1表示负数
-
形式值: 二进制转化成十进制的真是的值,即为形式值
-
真值:最高位被符号位占用,去掉最高位表示的值为真值
-
原码:符号位+真值 例如{[+1]原 = 0000 0001 [-1]原 = 1000 0001}
-
补码:正数的补码就是其本身,负数的补码是在其原码的基础上, 符号位不变, 其余各位取反, 最后+1. (即在反码的基础上+1)
-
反码:正数的反码是其本身,负数的反码是在其原码的基础上, 符号位不变,其余各个位取反.
-
-
chapter2· 运算原则(满二进1原则)
-
原码相加: 1+1 = 10; 1+0=0; 0+0=0;
-
反码相加: 1+1 = 0+0 = 0; 1+0=0+1=1; 0+0 = 1+1=10;
-
补码相加: 1+1 =0; 1+0=1; 0+0=0;(有1为1,全1是0)
-
-
chapter3· 机器是如何进行二进制运算的(补码运算)?
- 机器运算时采用二进制代替十进制的方式想必大家都知道,但是机器是不能区分正负号的. 所以采用补码,最高位表示符号位. 0表示正(+),1表示负(-). 这样便可以将符号参与到运算中,比如: 1 +(-1) = 0000 0001(补码) + 1000 0001(补码) = 1000 0000(补码)=0(最高位为符号位)
-
-
3,如何计算基本类型取值范围
- java中计算值都是按照补码运算. 对于byte基础数据类型来说 1byte = 1字节 = 8bits
- byte正数最大值是 0111 1111(补码)=127,负数的最大值为1111 1111 负数最小值为 1000 0000
- byte取值范围是[1000 0000 ~ 0111 1111]=[-128 ~ 127] =[-2^7~2^7-1].
- 1byte = 8bit 由此类推int四个字节 4*8-1=31 取值大小为[-2^31~2^31-1].
- 需要注意的是由于-128是[1 0000 0000=-0]已经溢出,显然错误。顾-128是没有原码和反码的. 目前计算机里溢出不补位,正溢出则变副最大,负溢出变正最大,这是个环.
-
4, 试着解答一些疑问
-
(1) · char怎么存放文字的?
-
java采用Unicode编码方式,Unicode是一种编写方式,一个Unicode占两个字节,这也是java中char占两个字节的原因.由于程序语言越来越国际化 以前的Ascii英文编码不能供其他语言使用.Unicode是Ascii的完全超集.而且其中的UTF-8,UTF-16,UTF-32编码可以通过编译实现中文的传输.
-
(2) · 谈谈boolean?
-
在单个的boolean对象中,是用int类型表示boolean;在boolean数组中是单个boolean只占一个bit. JVM中并没有给出byte的具体得范围规定, 在运算效率和存储空间之间的选择,看具体JVM实现而定.
-
看到这儿,对数据怎样在底层运行应该有个大概的认识了吧,接下来我们看点更刺激的吧.
内存分配
jvm内存可以分为运行时内存和直接内存两种.其中运行时内存是jvm主要活动的区域,从jvm装载类到初始化对象,存储对象等.
-
1,运行时内存
chapter1· 线程共享内存
-
(1), 方法区栈&运行时常量池
-
方法区栈(也叫永久代)
用来存放一些虚拟机预编译和编译后产生的Class文件代码数据以及Class的类信息、常量、静态变量等数据. 方法区是常量池的父集, 在jvm编译代码的时候就必须在内存中做好准备了,包括类的信息,类之间的关系以及类中的常量和静态变量.
-
运行时常量池
方法区中除了存储类信息的内存(类的引用符号),其他属于常量池内存. 在编译时类中定义的常量数据和静态变量数据, 便会在类加载的时候就已经在常量池中分配了内存. 需要注意的是,类中定义的常量虽然会在编译时分配好内存,但是在运行时的也是可以定义常量的. 为方便理解,举一下栗子:
-
以下两种声明常量方式有什么区别呢?
- a),public static final HANDSOME_JOEY boolean = true;
-
b),public final HANDSOME_JOEY boolean =true;
- 区别在于a在类装载就生成了对象并分配了内存,而b在每次声明类对象的时候都会重新 分配内存. 因为a声明的静态变量在编译的时候已经分配内存,final的存在导致声明后便不可更改。 然而b每次在依赖类对象后分配内存,类对象被回收后又会重新生成新的引用地址。 由于jvm使用了常量 折叠技术,final生成的常量将会代替符号表达式,在编译后用常量代替表达式。
-
-
(2), 堆内存
不同于上面的栈,堆的动态扩展性比较强. 主要用来存放运行时产生的java对象和数组的逻辑上的一块内存区.java堆虽然可以 在内存中线程共享,但也可以在堆中划分线程私有的缓冲区(Thread Local Allocation Buffer,TLAB). java堆按照GC算法可以细分为以下:
-
新生代:
刚生成的对象会存放在新生代,如果存在一定时间还没有回收,通过复制算法Copy到新生代另一个区域(Survivor).新生代一般被GC次数较多,一般占堆的1/3.
-
老年代:
在经过了新生代后,还没有被回收,就会进入老年代(大对象会直接进入老年代),老年代的对象需要通过 Full GC才能被回收,然而Full GC的调用次数会比较少(后面详细介绍GC策略).
-
chapter2· 线程私有内存
-
(1), 虚拟机栈
简单的理解: java在执行方法时存储局部变量表等信息,为java方法提供存储位置. 本地变量表以栈帧的形式存放方法(一个方法对应一个栈帧)已知的数据类型、对象句柄. 局部变量表会以slot为单位存放数据
-
(2), 本地方法栈
与虚拟机栈类似,唯一不通在于本地方法服务于Native本地方法. 这只是概念上的划分,在 hotspot(通过 java -version查看虚拟机信息) 虚拟机上与方法区属于同一栈区.
-
(3), 程序计数器
比较小的一块内存,控制运行时的执行行数、控制跳转(异常捕获,循环,判断,goto,挂起等),不服务于Native方法.
-
-
2,直接内存
chapter1· 什么是直接内存:
- 直接内存的狭隘定义是除了JVM运行时内存后留下来的一部分内存,有默认的大小.
- HotSpot虚拟机可以通过ByteBuffer调用DirectByteBuffer申请堆外内存.除非有很大的优势否则不要使用直接内存.
- 由于直接内存对象比较小,然而java开发者不会太过关注系统GC,如果不能触发full gc,迟早会内存溢出.
chapter2· 直接内存的优势:
- JNI方法使用的本地方法栈内存和Heap其它内存交互,会copy一份到堆外作为缓冲区(因为复制两个副本会比较浪费资源)直接使用堆外内存省去一些时间.
- 堆外内存在读写时速度比堆内存快.
- 堆内存不属于jvm托管,数据对象比较持久,可以跨进程共享.
- 可以扩展jvm之外的内存供进程使用.
chapter3· 直接内存的缺点:
- JVM没有托管该内存区域,会出现内存不可控状态
- 改区域内存回收不及时也将内存溢出
- 使用接口的数据类型比较单一,使用比较麻烦
chapter4· 代码(引用自网络)示例:
/**
* 测试DirectMemory和Heap内存申请速度。
*/
public void testDirectMemoryAllocate() {
long tsStart = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
ByteBuffer buffer = ByteBuffer.allocateDirect(400);
}
System.out.println("DirectMemory申请内存耗用: " +
(System.currentTimeMillis() - tsStart) + " ms");
tsStart = System.currentTimeMillis();
for (int i = 0; i < 100000; i++) {
ByteBuffer buffer = ByteBuffer.allocate(400);
}
System.out.println("Heap申请内存耗用: " + (System.currentTimeMillis() - tsStart) + " ms");
}
/**
* 测试DirectMemory和Heap读写速度。
*/
public void testDirectMemoryWriteAndReadSpeed() {
long tsStart = System.currentTimeMillis();
ByteBuffer buffer = ByteBuffer.allocateDirect(400);
for (int i = 0; i < 100000; i++) {
for (int j = 0; j < 100; j++) {
buffer.putInt(j);
}
buffer.flip();
for (byte j = 0; j < 100; j++) {
buffer.getInt();
}
buffer.clear();
}
System.out.println("DirectMemory读写耗用: " + (System.currentTimeMillis() - tsStart) + " ms");
tsStart = System.currentTimeMillis();
buffer = ByteBuffer.allocate(400);
for (int i = 0; i < 100000; i++) {
for (int j = 0; j < 100; j++) {
buffer.putInt(j);
}
buffer.flip();
for (byte j = 0; j < 100; j++) {
buffer.getInt();
}
buffer.clear();
}
System.out.println("Heap读写耗用: " + (System.currentTimeMillis() - tsStart) + " ms");
}
对象生成
要实例化一个对象,我们首先需要检查对象是否已经装载了对应的类,然后组装出一个对象(地址信息,分区信息,唯一哈希值等).
-
1,对象初始化
chapter1 · 类的引用是存在常量池中,通过常量池的引用找到内存的真实地址.
- 1, 检查该对象在常量池中是否找到类的符号引用
- 2, 该符号所代表的类是否加载过,若没有加载,需执行类加载过程
- 数组对象和Class对象比较特别,不在讨论范围.
-
2,组装对象
chapter1 · 对象头(Header)
- 1, 对象唯一哈希码(HashCode).
- 2, GC分区信息
- 3, 元数据信息
-
….
- 关于哈希码:HashMap存值得key便是对象的HashCode.例如:下面伪代码中因为a和c的HashCode不一致,”i get c too” 是不会打印的:
HashMap map = new HashMap();
int a = 1;
int b = 2;
int c = 3;
a=b;
map.put(a,c);
if(map.get(a)==c)
System.out("i get c");
if(map.get(b)==c)
System.out("i get c too");
-
chapter2 · 对象数据部分(Data)
- 对象所携带的数据
-
chapter3 · 对齐填充(Padding)
- 虚拟机执行有自己的格式(int四个字节,char两个字节),一般情况下数据是需要高位补齐填充的.
-
3,对象寻址
- 句柄:是指指向指针的指针,可以通过句柄作为中介寻址.
- 引用:对象的别名,经过改装过的指针.
- 指针:是指对象在内存中的地址.
-
chapter1 · 直接指针访问定位, 通过指针直接定位对象
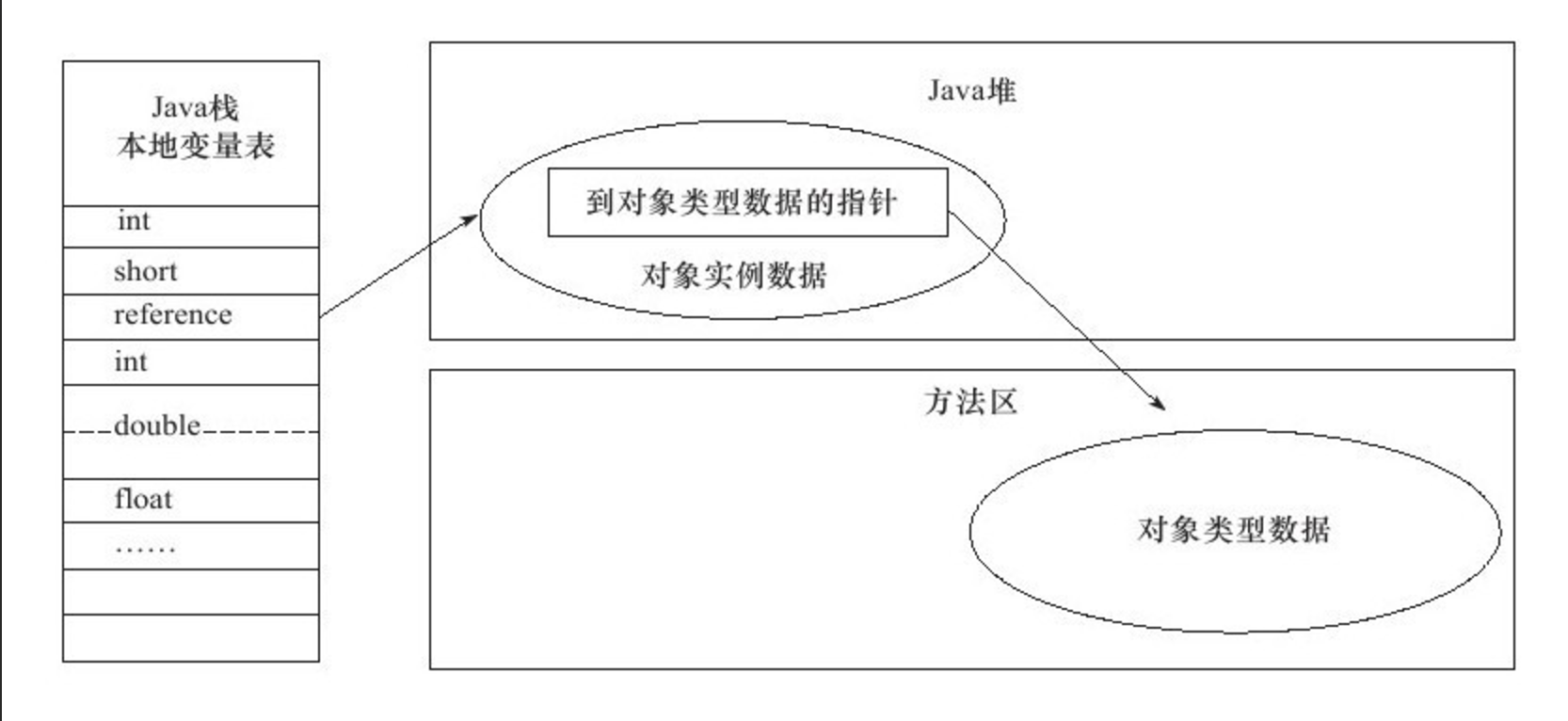
引用指向堆内存区,内存区中有对象在方法区的指针和对象的实例数据.
-
chapter2 · 句柄定位,通过指针找到句柄,通过句柄找到对象.
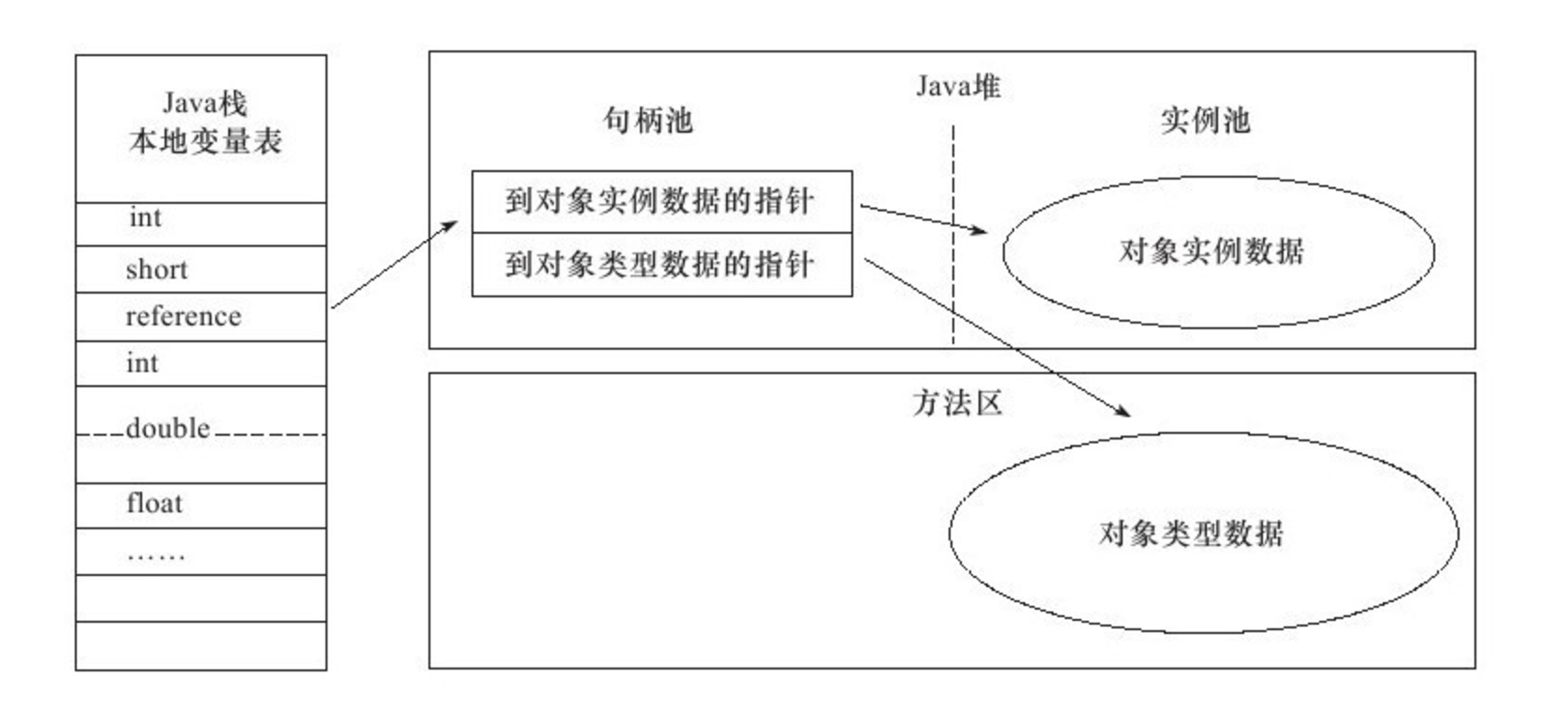
引用持有对象的句柄,句柄中包含有对象方法区的指针和实例数据的指针.
-
直接定义与句柄定位区别: 在jvm垃圾回收时,对象会移动到不同的内存区(会改变对象的指针,对象本身无需修改).直接引用的对象中会存放一些地址信息,句柄引用需要通过句柄重新定位指针间接寻址.句柄在找到对象比直接指针会慢,不同虚拟机有不同实现方式.
内存回收
-
1,怎样判定对象可以GC
-
chapter1 · 回收引用时判定算法
-
引用计数器算法:通过给引用中添加引用计数器的方式. 有地方持有其引用时计数器加1,引用失效后减一.当计数器为0时便判定没有地方持有该对象引用,即可判定引用可以被回收;
-
在《深入理解java虚拟机》一书中,看到以下问题:引用计数器算法是有缺陷的.就是当对象互相拥有其引用时而没有其他引用,这个时候应该被回收,但是如果采用技术器算法 由于计数器并不是0,将导致这两个对象永远都不会被回收。作者提出了如下算法:
-
可达性分析算法(图片引用自《深入理解java虚拟机》一书):
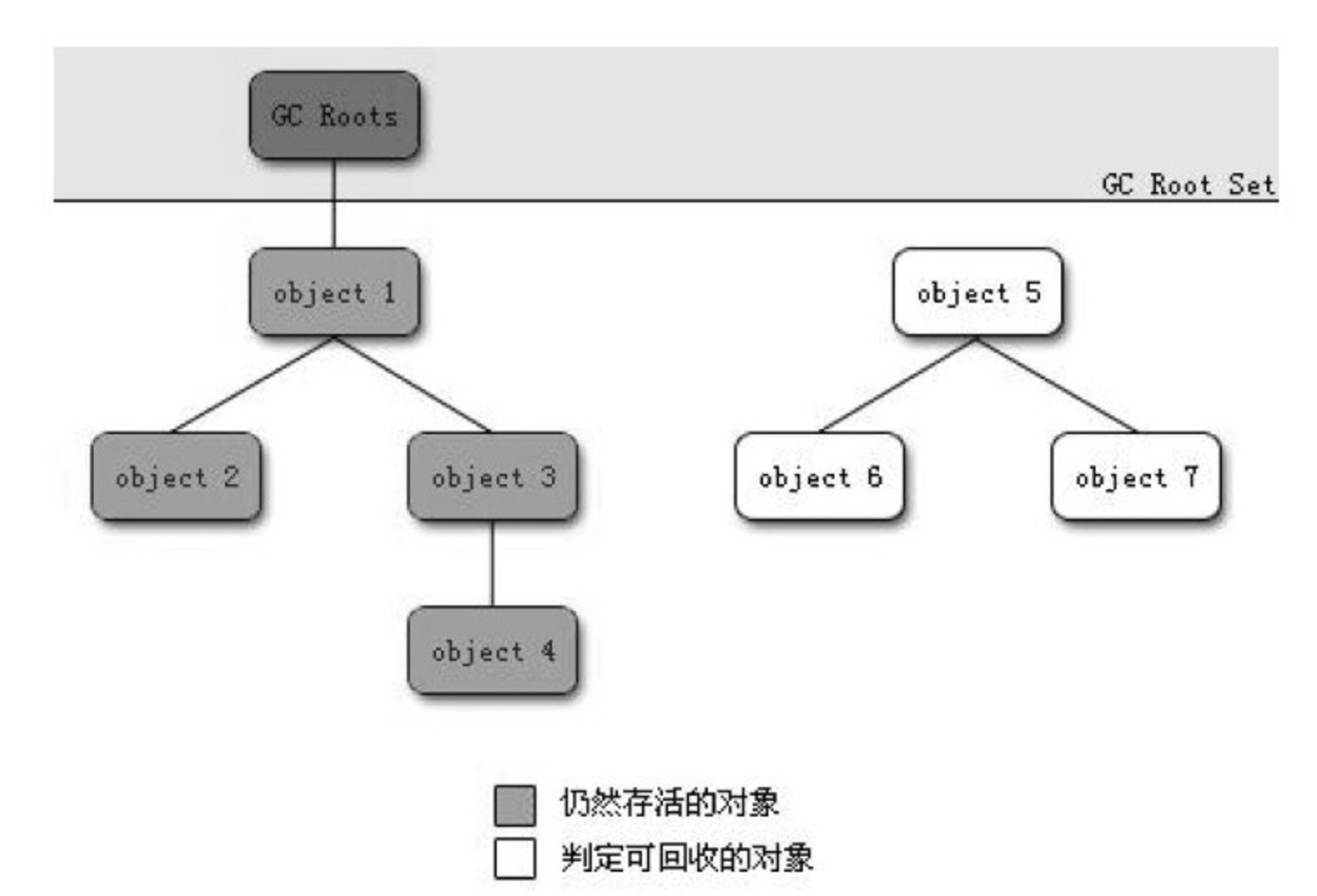
从GCRoot开始往下遍历图,当GCRoot和object不可达时(GCRoot和object不能直连),即表示可以回收。上图中Object5,Object6,Object7就是可以回收的情况
-
-
-
-
2,回收方法区和堆区的对象
程序计数器、虚拟机栈、本地方法栈是线程独享.由于jvm中的定义的方法数量和类数量是可控的,栈可以按照执行顺序自己控制对象生命周期.
-
chapter1 · 方法区回收
-
常量:与堆中的对象回收机制类似.当一个常量定义好并存在于常量池中时,当前环境并没有该常量的引用,如果系统发生GC,该对象可能会被清理出常量池.
-
类回收要满足以下三个条件 :
-
在堆中不存在任何该类的实例引用;
-
加载该类的ClassLoader被回收
-
该类的Class对象没有在其他地方引用.
-
-
-
chapter2 · 堆内存回收
-
年轻代分为三个区域:
-
Eden区:刚新建的对象会在年轻代中生成(大对象会在老年代生成)
-
两个对称分布的Survivor区:Eden区满后会出现在Survivor区.
-
新生代回收对象比较讲究效率,采用的是单线程的Serial New收集器和Copy算法.
-
-
老年代: 存放一些来自新生代仍旧没有被回收的或者比较大的对象
-
GC方式(越是老年区,对象生命越顽强):
-
年轻代采用Minor GC方式,将Eden区清空移至Survivor区,如果Survivor区满了就会移到老年代区
-
Full GC : 对整个堆进行回收,Full GC发生频率较小,一般在系统内存严重不足时发生.System.gc()方法可以建议jvm进行FULL GC,不过此gc方式比较效率比较低,不能频繁调用.
-
-
-
-
3,关于引用
-
强引用(Strong Reference)
一般对象引用默认为强引用,如果强引用通过以上判定为不能GC.那么即使发生OutofMemory系统也不会回收。
-
软引用(Soft Reference)
SoftReference类可以实现对象为软引用,用于声明有用但非必须的对象.如果系统即将发生内存溢出,垃圾收集器将会把软引用作为回收对象. 如果回收后内存仍不足,还是会发生内存溢出.
-
弱引用(Weak Reference)
WeakReference类可以实现对象为虚引用,用于声明非必须的对象.回收优先级高于软引用.
-
虚引用(Phantom Reference)
PhantomReference类来实现虚引用,虚引用不用来表示引用关系.一般用于系统在GC时可以收到系统的通知。代码如下:
-
String x = new String("hello joey");
final ReferenceQueue<String> referenceQueue = new ReferenceQueue<String>();
new Thread() {
public void run() {
while (isOpen) {
Object obj = referenceQueue.poll();
if (obj != null) {
try {
Field rereferent = Reference.class
.getDeclaredField("referent");
rereferent.setAccessible(true);
Object result = rereferent.get(obj);
//如果收到通知,即证明该对象被回收.
System.out.println("gc will collect:"
+ result.getClass() + "@"
+ result.hashCode() + "\t"
+ (String) result);
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
}.start();
//关联ReferenceQueue,系统在回收的时候回添加到ReferenceQueue中.
PhantomReference<String> abcWeakRef = new PhantomReference<String>(abc,
referenceQueue);
//将引用取消
abc = null;
Thread.currentThread().sleep(3000);
//通知系统回收
System.gc();
Thread.currentThqread().sleep(3000);
isRun = false;